31
Mar
The dataset consists of 3 classes namely setosa versicolour virginica and on the basis of certain features like sepal length sepal width petal length petal width we have to predict the class. For regression the measure of impurity is variance.
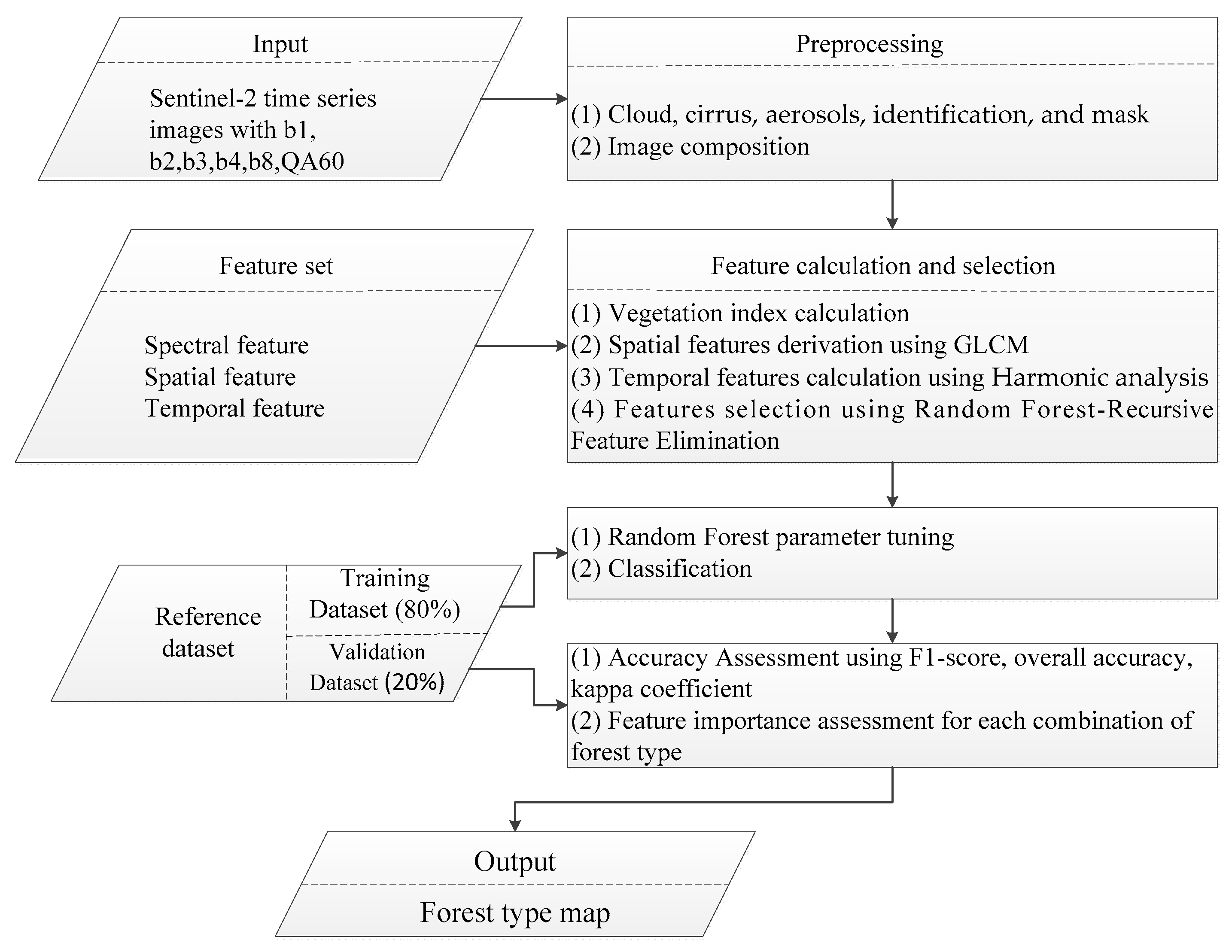
Features of forest classification. Forests have been classified in different ways. They have been classified according to the Biomes in which they exist combined with leaf longevity of the dominant Species ie. Whether they are evergreen or deciduous.
Another Classification is classified whether the Forests are composed predominantly of Broad-Leaf Trees Coniferous needle-leaved Trees or Mixed. Overview of Random Forest Classification. Random Forest is also a Tree-based algorithm that uses the qualities features of multiple Decision Trees for making decisions.
Therefore it can be referred to as a Forest of trees and hence the name Random Forest. The term Random is due to the fact that this algorithm is a forest of Randomly created Decision Trees. Characteristics of the tropical foresthigh animal and vegetal biodiversityevergreen treesdark and sparse undergrowth interspersed with clearingsscanty litter.
We will then build our features dataset that will be fed into our classifier. Build the features features for i in rangelenencodedWeather. FeaturesappendencodedWeatheri encodedTimeOfWeeki encodedTimeOfDayi Now its time to train our random forest classifier by using the RandomForestClassifier class from Scikit-Learn.
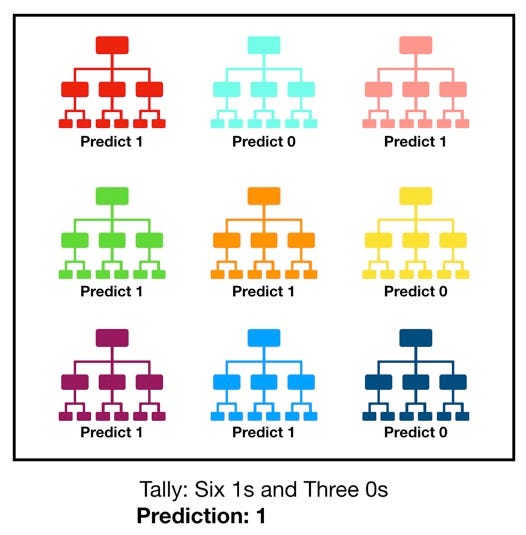
In machine learning there are many classification algorithms that include KNN Logistics Regression Naive Bayes Decision tree but Random forest classifier is at the top when it comes to classification tasks. Random Forest comes from ensemble methods that are combinations of different or the same algorithms that are used in classification tasks. The random forest comes under a supervised algorithm that can be used for both classifications.
This example shows the use of a forest of trees to evaluate the importance of features on an artificial classification task. The blue bars are the feature importances of the forest along with their inter-trees variability represented by the error bars. As expected the plot suggests that 3 features are informative while the remaining are not.
The features for internal nodes are selected with some criterion which for classification tasks can be gini impurity or infomation gain and for regression is variance reduction. We can measure how each feature decrease the impurity of the split the feature with highest decrease is selected for internal node. For classification the measure of impurity is either the Gini impurity or the information gainentropy.
For regression the measure of impurity is variance. Therefore when training a tree it is possible to compute how much each feature decreases the impurity. The more a feature decreases the impurity the more important the feature is.
The dataset consists of 3 classes namely setosa versicolour virginica and on the basis of certain features like sepal length sepal width petal length petal width we have to predict the class. Features of forest classification Get the answers you need now. Theshaikharshad2405 theshaikharshad2405 09062019 Geography Secondary School 5 pts.
Answered Features of forest classification 2. The ideal classification for forest management is one which satisfies the needs of the forest administrative planners with up-to-date information at minimum time cost and also to improve the ability of the planner and appraise him of the condition characteristics the resource potential and the environmental constraints in the. However some people told me that you have many features.
Hence at first you have to perform feature selection or pca before random forest classification. I generally choose 10 maybe 20 features when performing random forest. It has a special parameter which specifies max features and I choose 20 or 30 decision trees for classification.
Forest area divided into 1reserved forest 2protected forest 3unclass forest 39. SALIENT FEATURES OF 1988 Maintenance of environmental stability through preservation and where necessary restoration of the ecological balance that has been adversely disturbed by serious depletion of the forests of the country. Conserving the natural heritage of the country by preserving the remaining natural.
In forest classification the unit is typically the homogeneous stand with respect to species composition structure and function and on the basis of the final objective management research pleasure protection the classification process requires a. Since random forest can handle both regression and classification tasks with a high degree of accuracy it is a popular method among data scientists. Feature bagging also makes the random forest classifier an effective tool for estimating missing values as it maintains accuracy when a portion of the data is missing.
Using Random forest algorithm the feature importance can be measured as the average impurity decrease computed from all decision trees in the forest. This is irrespective of the fact whether the data is linear or non-linear linearly inseparable Sklearn RandomForestClassifier for. Its called Forest-based Classification and Regression and it lets analysts effectively design test and deploy predictive models.
Forest-based Classification and Regression applies Leo Breimans. The Random forest or Random Decision Forest is a supervised Machine learning algorithm used for classification regression and other tasks using decision trees. The Random forest classifier creates a set of decision trees from a randomly selected subset of the training set.
Previous post
Fedex carbon neutral shippingNext post
Fatal injuries between 1974 and 2011